
.png?width=1280&height=720&name=LinkedIn%20test%20(29).png)
Research
Text recognition models
What sets Transkribus apart from other text recognition platforms? The ability to train your own custom models. This powerful tool allows you to move beyond generic text recognition and create a model perfectly tailored to your specific documents, resulting in more accurate transcriptions and less manual correction.
While the idea of training an AI model might seem intimidating, Transkribus was specifically designed for historians, researchers, and archivists — not computer scientists. You don’t need a technical background to achieve professional-level results. In this tutorial, we will guide you step-by-step through the process, showing you how to build a highly effective model that will take your project to the next level.

Step 1: Prepare your training data
Training an accurate model starts with high-quality training data, known as Ground Truth. This training data consists of two parts: images of your documents and perfect, word-for-word transcriptions of those images. The model carefully compares the image to the text to figure out how characters and words are formed. The more accurate your Ground Truth, the more accurate your final model will be.
Preparing your training data is the most time-consuming part of training a model. This is how to do it:
- Upload your documents: Add your document images to a collection in Transkribus.
- Generate an automatic transcription: Perform automatic text recognition on the selected pages using a generic model, such as the Text Titan I, to create an automatic transcription. Alternatively, you can manually transcribe the documents from scratch, although this generally takes longer than generating and editing an automatic transcription.
- Correct the transcription: Manually edit the generated transcription to ensure it is completely accurate and consistent. The model will replicate any errors present in the Ground Truth, so precision is critical.
- Set status to Ground Truth: Once a page is fully corrected, change its status in the page's metadata to Ground Truth.
The amount of data required depends on the material. Printed documents generally need around 5,000 words for good results. For more variable handwritten text, a minimum of 10,000 words per hand is necessary. Large models trained on over 100,000 words can even learn to read new, unseen handwriting.
Step 2: Model setup and training
Once you have prepared your Ground Truth, you are ready to start training your model.
- Open the Training Lab: Navigate to Models → Training Lab → Train new model.
- Choose your training data: Select which pages you want to train the model on. These should be the pages you set as Ground Truth in Step 1.
- Select your validation data: Next, choose which pages you want to test your model on. As a general rule of thumb, 90% of your Ground Truth should be training data and 10% should be validation data.
- Enter metadata for your model: Add information such as a name and description and specify whether you want to use a base model or not.
- Start the training: After selecting your training and validation data, you can begin the training process.
The training process can take some time, depending on the amount of data you are using and the complexity of your documents. You will be notified by email once the training is complete.
Step 3: Understanding and improving your model
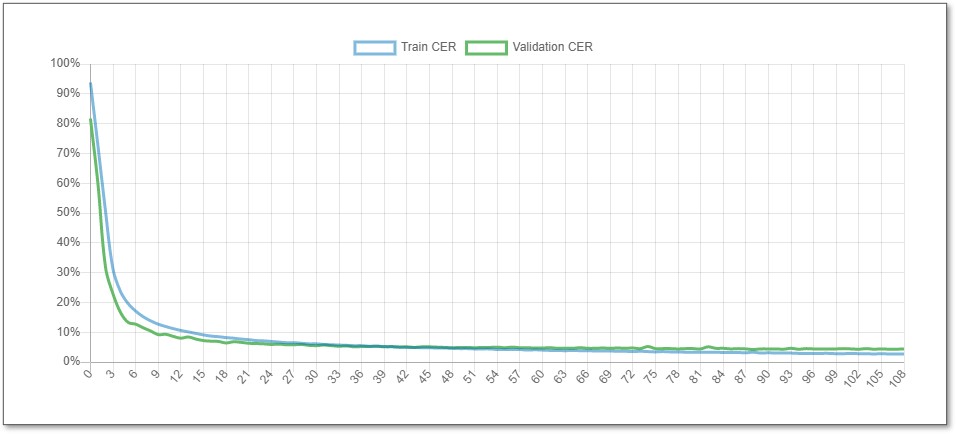
Once training is complete, you can check your model’s performance in the Training Lab. The key metric is the Character Error Rate (CER), which measures the percentage of incorrectly transcribed characters. A lower CER means a more accurate model. While a CER under 1% is achievable for simple printed text, a CER of 5% or less is a great result for complex handwriting.
You will also see a learning curve graph, which shows how the model's CER decreased during training. A steady downward slope indicates successful learning. Don’t worry if your initial CER isn’t perfect. You can significantly improve your model’s accuracy by adding more Ground Truth and retraining it. For more detailed advice, check out our guides on how to improve the CER of your model and how to retrain a model in Transkribus.
Finally, it’s always a good idea to test your new model on a few pages that weren't used for training to see how it performs on unseen material.
Where can I find out more?
This post gives you a basic overview of how to train a text recognition model in Transkribus. If you would like to learn more, we have a range of resources that can help:
- The Transkribus Help Center is a great place to start. It contains detailed articles and tutorials on every aspect of the Transkribus software, including an in-depth guide to training a text recognition model.
- We also have a recording of our "How to Train a Model" webinar available on our YouTube channel (or see above). In this webinar, our experts walk you through the entire process of training a model, from preparing your data to understanding the results.
