
.png?width=1280&height=720&name=LinkedIn%20test%20(13).png)
We are excited to share the Text Titan I ter (TTI ter), the newest iteration of our general-purpose text recognition models. TTI ter is trained on a substantially expanded dataset of 31 million words, delivering our best out-of-the-box accuracy yet with a wide range of historical documents, whether handwritten or printed, common or unusual, historic or modern, in English, German, French, Dutch or any other language in the Latin script.
In this blog post, we will take a look at what makes the Text Titan I ter different to our other Super Models, and see how its ability to transcribe historical documents compares to the leading Large Language Models (LLMs): ChatGPT, Gemini, Claude, and Mistral.
What’s new
- A 30% reduction in character error rate compared to Text Titan I for both printed and handwritten text.
- A lower character error rate than any language-specific Super Models, such as the German Genius and Dutch Dean
- Comparative benchmarks show ~3x lower character error rates than the best performing LLMS tested
- Available today for Scholar, Team, and Organisation subscribers
How we test: Creating “general” historical benchmarks
To test the performance of our models against leading LLMs, we developed a comprehensive text recognition benchmark using a representative sample from our collection of historical documents. From our corpus of 7 million pages, spanning approximately 9,000 archival sources, we selected a representative sample of 2,000 pages. These pages are excluded from the training sets of all models to serve as an independent evaluation benchmark.
The benchmark includes:
- Documents in 13 different languages
- Printed and handwritten text
- A huge variety of writing styles, layouts and documents
We measure accuracy using Character Error Rate (CER) — essentially what percentage of characters the model gets wrong, where lower scores indicate better performance. This is measured at the full-page level. For reference, a CER under 5% usually means the text needs minimal correction; a CER around 10% is usually readable with some corrections needed; and anything over 20% may be unreadable or needs significant manual correction.
Note: LLMs frequently refuse to transcribe complex historical documents, responding with messages like “I cannot provide a transcription”. In these cases, the transcription is empty, so the CER for the document is automatically 100%.
The results: TTI ter vs. state-of-the-art models
These benchmarks indicate that TTI ter achieves substantially lower character error rates than all tested LLMs on both printed and handwritten historical documents.
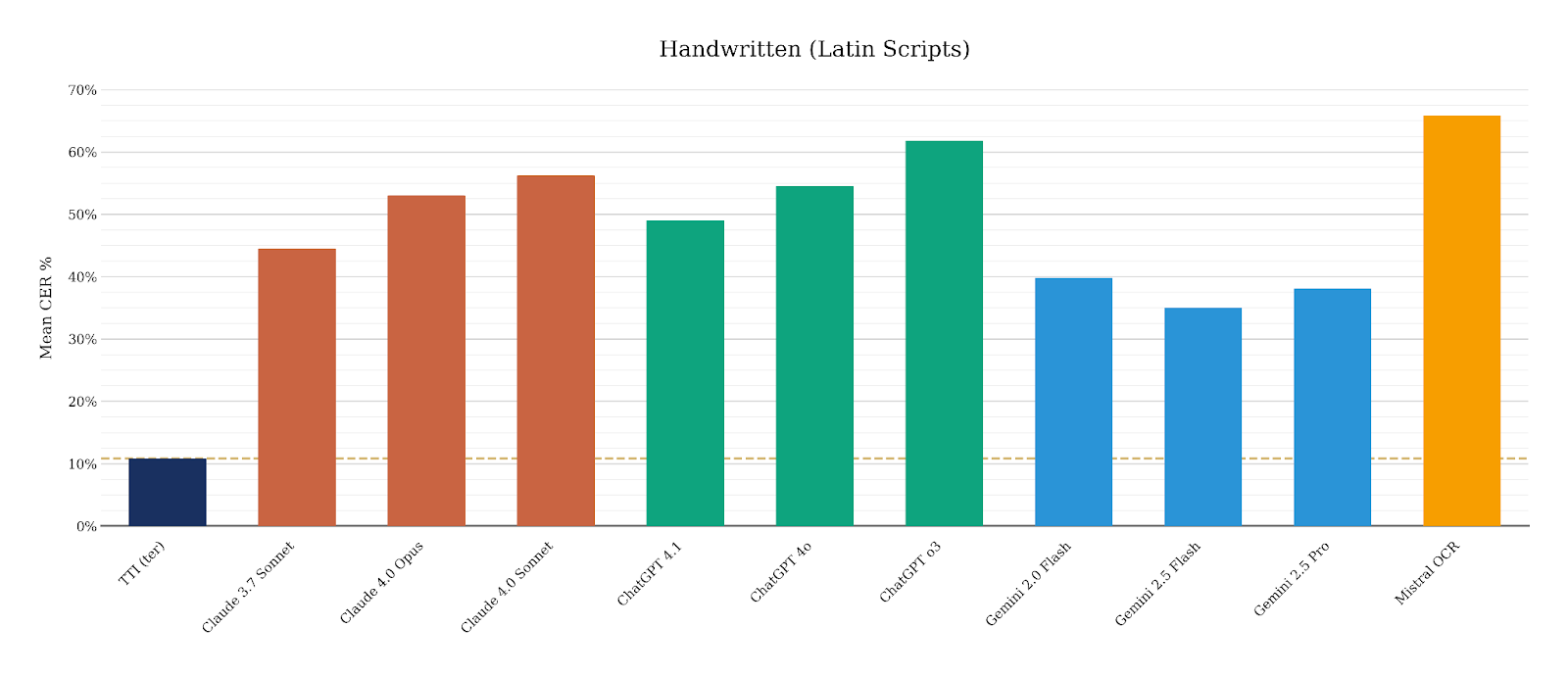
Handwritten text recognition
TTI ter (10.8% CER) produces transcripts that are 3.2x more accurate than the best competing LLM, Gemini 2.5 Flash (35.0% CER).
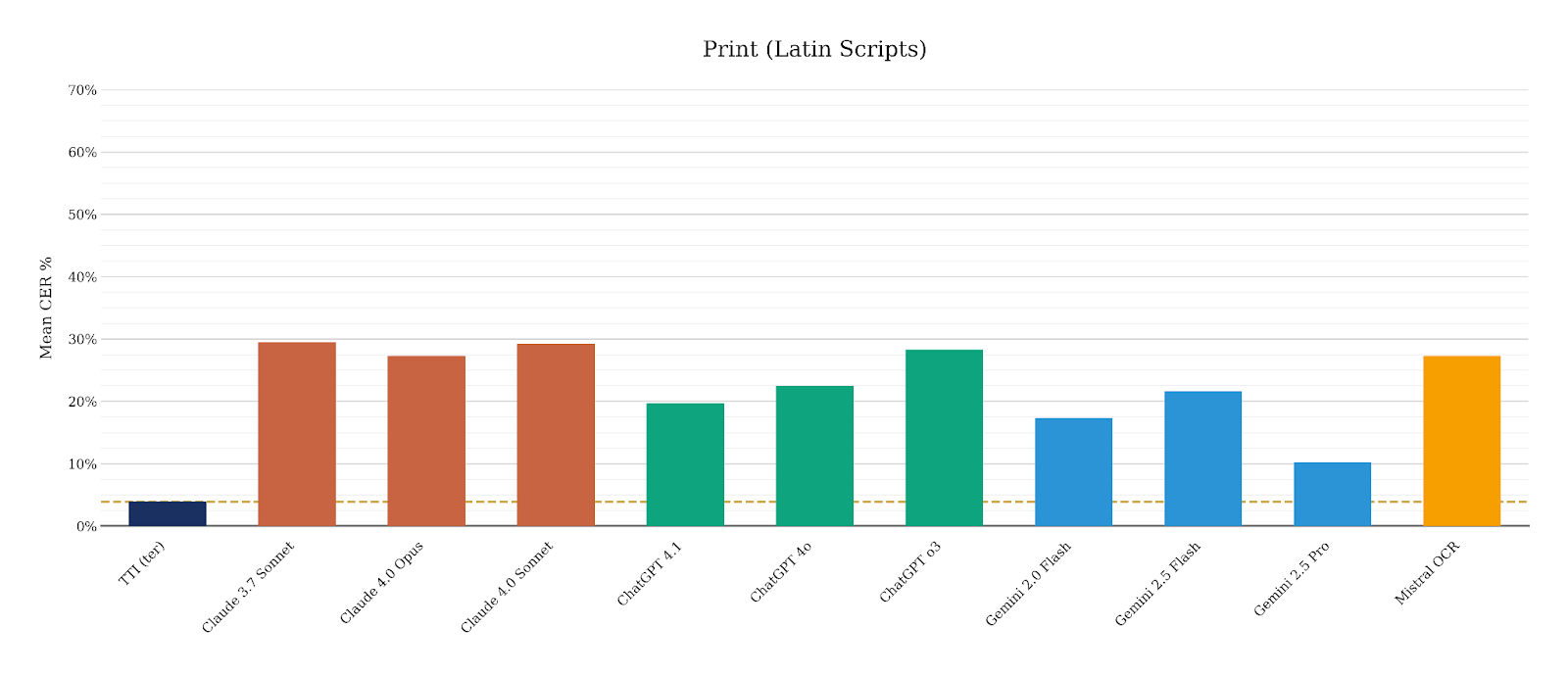
Printed text recognition
For printed text recognition, where the gap is smaller, TTI ter achieves a CER of 3.9%, representing a 2.6x reduction in error rate compared to Gemini 2.5 Pro (10.2% CER), the best-performing LLM in this category.
Performance across languages
TTI ter maintains consistent performance across multiple languages:
- Dutch: 7.2% CER (3.4x better than the best LLM, Gemini 2.5 Flash at 24.2%).
- English: 11.5% CER (2.0x better than the best LLM, Gemini 2.5 Flash at 22.5%).
- French: 9.1% CER (2.5x better than the best LLM, Gemini 2.5 Pro at 23.2%).
- German: 8.6% CER (4.0x better than the best LLM, Gemini 2.0 Flash at 34.7% CER).
- Other Languages: 9.6% CER (3.4x better than the best LLM). This includes Danish, Finnish, Italian, Latin, Norwegian, Polish, Portuguese, Spanish, and Swedish.
The Text Titan journey
The progression from the original Text Titan to TTI ter shows consistent, progressive improvements. TTI ter achieves approximately 30% lower error rates than the original Text Titan model for both handwritten and printed text.
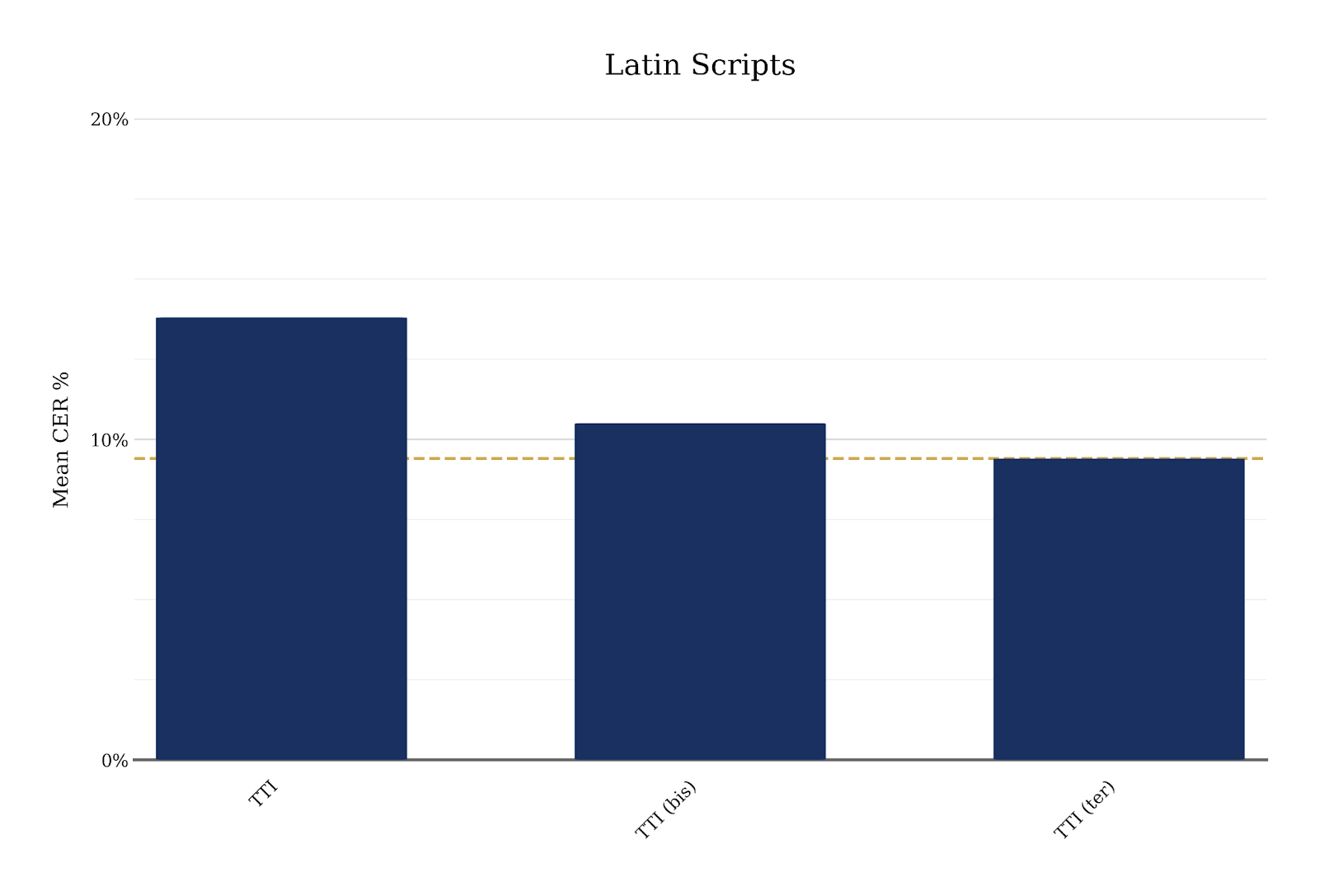
Notably, the TTI ter achieves lower error rates than all tested language-specific Super Models in the Transkribus platform:
- English: 11.5% CER (7% better than the English Elder at 12.3% CER).
- Dutch: 7.2% CER (3% better than the Dutch Dean at 7.4% CER).
- German: 8.6% CER (4% better than the German Genius at 9.0% CER).
These results show that the TTI ter can process multilingual collections effectively, without the need to switch models.
A typical transcription
To illustrate what you can expect with the TTI ter, we asked it to transcribe the historical document with the median character error rate from our benchmark. This means this is the average difficulty document. You can see the result below:

5.
settl'd on His Male Heirs.
The Clergy & Commons came to the Senate the 10th of Nov
to demand their final resolution; but finding they
sought only for delay, went in a Body to the King, & carried
him the above Declaration, who thank'd them for their
good will, but said He could not accept their offer,
unless the Senate join'd with them
The Nobility seem resolv'd to leave the City, which would
have dissolv'd the Diet; but were prevented by the
Gates being kept Shut; & found themselves obligt the 13th.
to agree to the proposals of the Clergy &c. & they at or
the 16th gave back to the King, the instrument of
Government that late bound to His Power; & two or
three months after the three Orders brought Him
Seperately Declarations Sign'd under their hands,
by which they settl’d the Corwn both on His Male
& Female Heirs, with absolute Forces & the right
of regulating the Succession & Regency.
What’s next
Text Titan I ter is the most recent model in the Text Titan series and is now available on Transkribus. Benchmark results demonstrate substantial improvements over Text Titan I and lower error rates than all tested language-specific models. For historical text recognition, TTI ter achieves substantially lower error rates than leading LLMs. As our research continues, we look forward to sharing future developments with the Transkribus community.
Try it yourself
Ready to experience the improvements for yourself? Access Text Titan I ter today and see how it performs on your historical documents.

.png?width=1280&height=720&name=SuS%20Template%20(1).png)