
%20(1)-1.jpg?width=1928&height=1088&name=Field%20Models%20launch%20thumbnail%20(1)%20(1)-1.jpg)





Research
Text recognition models
Field Models - our powerful, trainable models for structural layout recognition - are now live!
After a successful beta phase, including continuous testing and valuable feedback from our community (who have already trained 500+ Field Models), we've fine-tuned this game-changing feature to be as efficient as possible. Whether you're working with newspapers, birth registers, or any other complex document, Field Models are here to improve your workflow and make it smarter.
Today we're pleased to announce that the new and improved Field Models are now available in the Transkribus app as part of the Scholar, Team, and Organisation subscription plans.
In this blog post, we'll give you a brief overview of the purpose and functionality of Field Models to help you decide if they're right for your project. We’ll also introduce you to our first two public Field Models, which are ideal for getting started with this new and exciting technology.
The importance of layout analysis
Creating an automatic transcription in Transkribus involves two main steps. First, the platform carries out a layout analysis to determine where the text is located on the page. Once the text is identified, the platform then deciphers the characters and words, producing a transcription. This second step is referred to as text recognition.
If your documents have a straightforward layout, such as a handwritten diary with straight lines of text, Transkribus can easily locate the text. However, documents with more complex layouts, such as newspapers with their multiple columns, varied text regions, headings, and embedded images, present a challenge for accurate layout extraction. Field Models help Transkribus identify and categorise these layout elements correctly, ensuring that the document's structure is preserved and understood in a semantically accurate manner.
.jpg?width=1298&height=686&name=Grundbuchbl%C3%A4tter%20(1).jpg)

With a Field Model, you can train Transkribus to recognise the complex layout of your documents. © Die Tiroler Grundbuchblätter der k. u. k. Armee via Transkribus
How Field Models improve layout analysis
Where layouts get complex is where Field Models become valuable. Field Models allow you to train a custom AI model to recognise complex layouts in your documents. Just as a text recognition model learns to recognise different handwriting styles, a Field Model learns to identify different layout elements, such as headlines, columns, or marginalia.
You can also use Transkribus to detect specific elements within your documents, such as page numbers or headings, and add these to an existing layout. This is particularly useful if you've already processed a document but now want to label and focus on particular layout components. During text recognition, you can choose the structural regions identified by the Field Model and restrict the text recognition to just those areas.
Additionally, you can train the model to recognise only certain parts of your document. For instance, if you need to extract only the heading and date, you can train a Field Model to identify these elements exclusively. When you run the text recognition, Transkribus will transcribe just these selected fields, eliminating the need to transcribe the entire page and then manually extract the desired parts. This targeted approach significantly streamlines your workflow, saving time and effort.
An example of how Field Models work
Let’s take a look at how this works in practice. In this example, you are wanting to digitise and transcribe a collection of newspaper index cards. Each card has several layout elements:
- a name
- a shelfmark
- the name of the newspaper
- a detailed description
- a reference
- an “In Basement” label.
The original index card. © Peabody Institute Library
You want to automatically transcribe everything on the index card except the “In Basement” label.
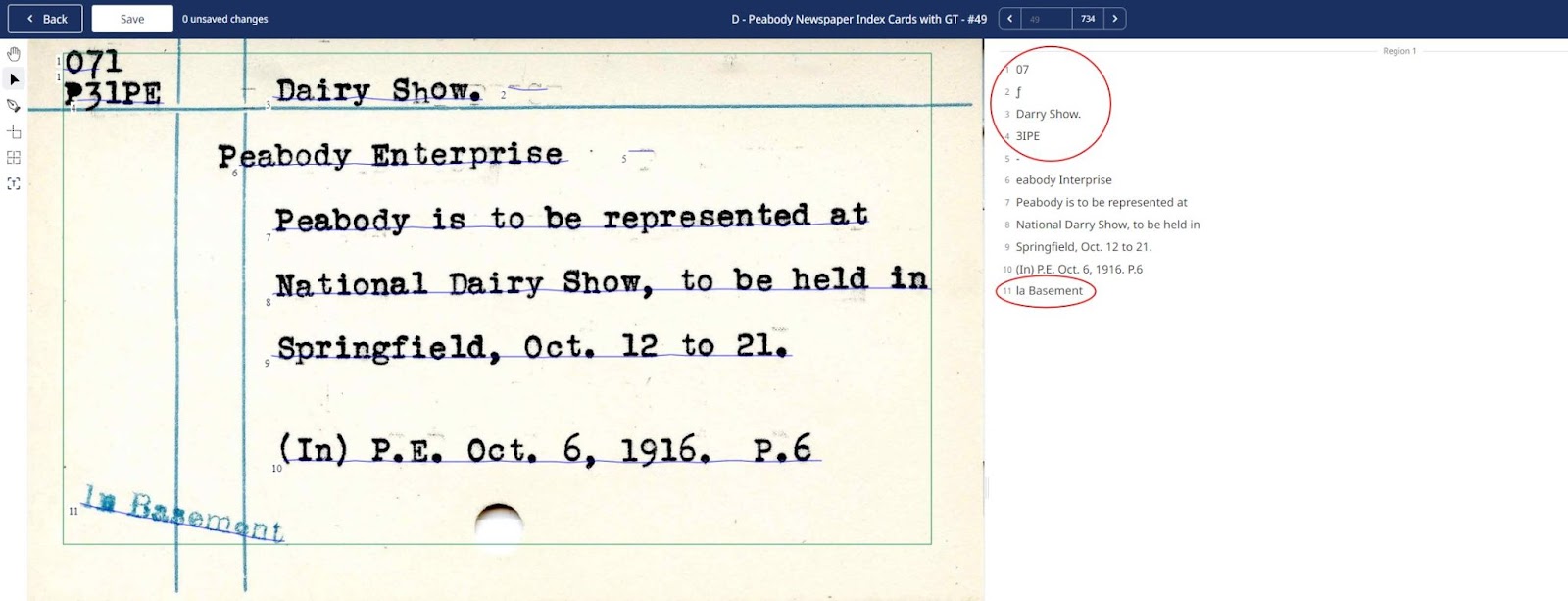
If you run the text recognition using Transkribus’ default layout analysis settings and without a Field Model, you will be left with a transcription that looks like this:
Transcribed index card without a Field Model being applied first. © Peabody Institute Library
When using the standard layout analysis in Transkribus, the text on an index card is transcribed as a continuous block without any structural information, treating all elements as part of the same undifferentiated text stream. This provides a basic transcription but lacks the detailed organisation necessary to accurately reflect the document’s structure.
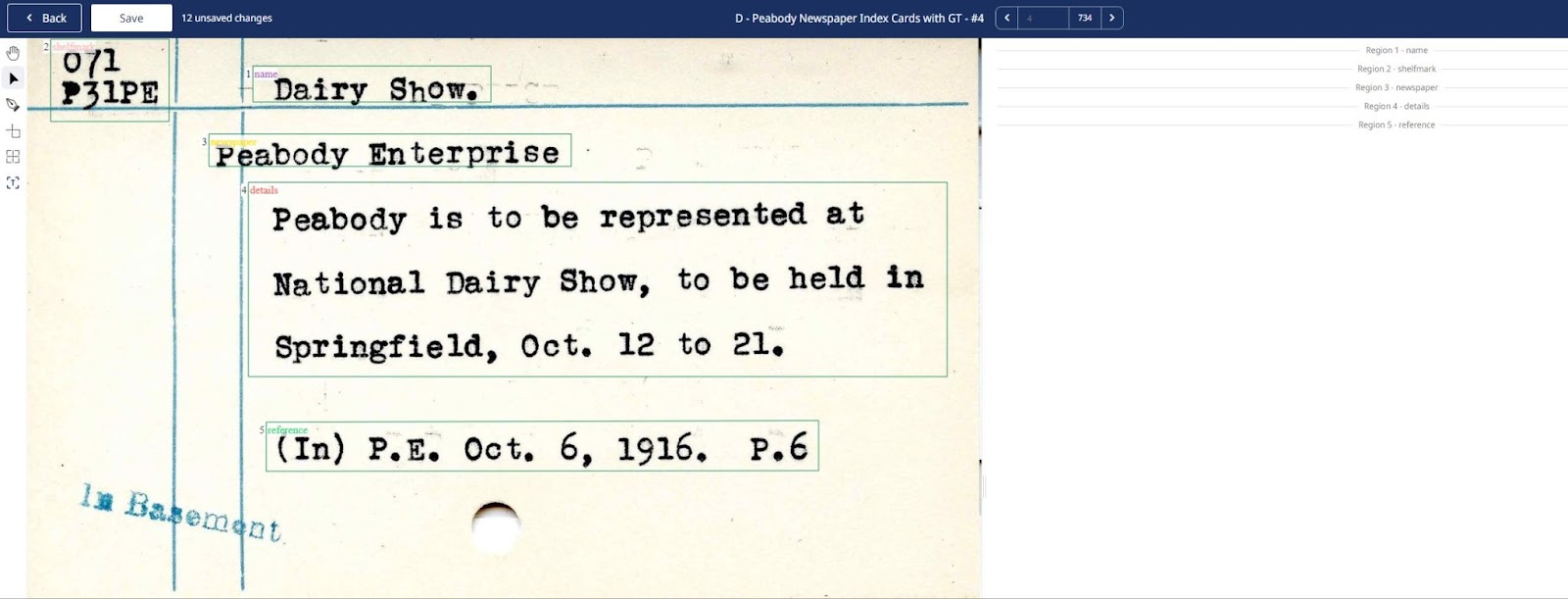
Index card after a Field Model has been applied. © Peabody Institute Library
In contrast, by applying a Field Model to the index card, Transkribus can recognise and preserve these distinct elements, such as the name, shelfmark, newspaper title, detailed description, and reference.
Note that as the Field Model was trained to not recognise the “In Basement” label, it has simply ignored this layout element.
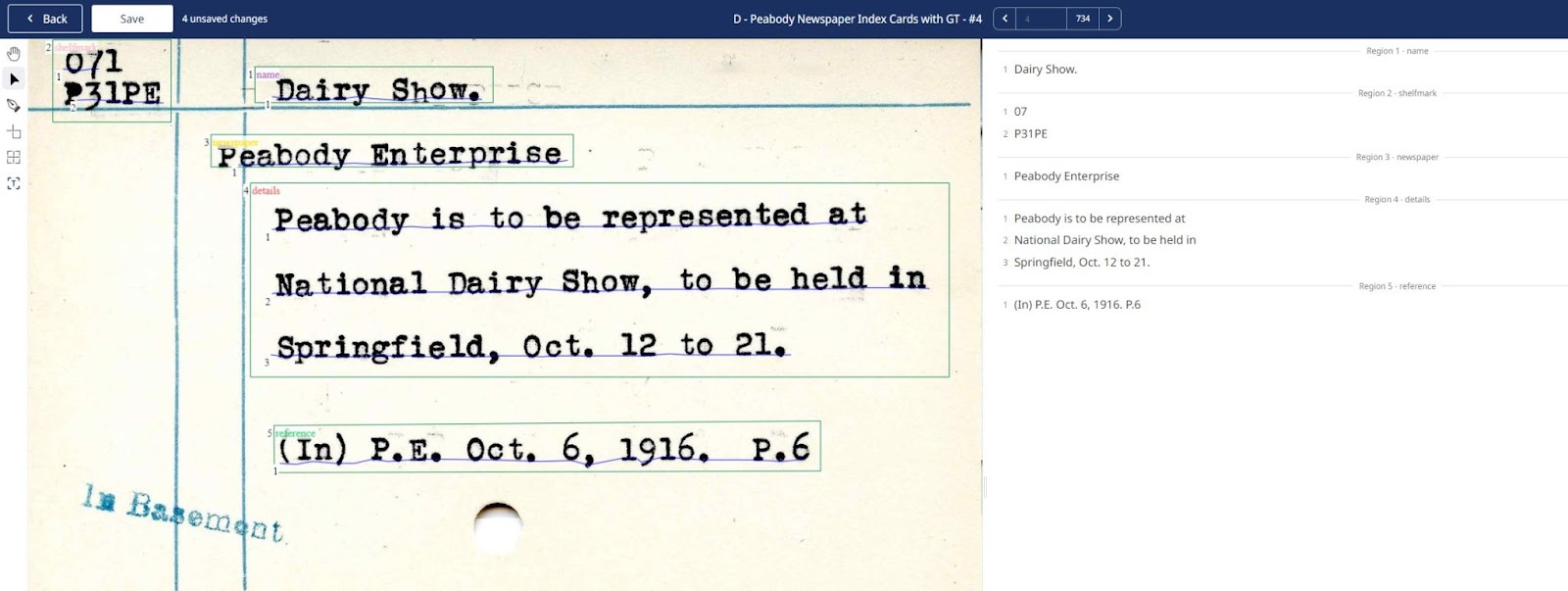
Finished index card after layout analysis with a Field Model and text recognition. © Peabody Institute Library
As you can see above, this results in a transcription that not only includes the text but also maintains the layout’s structure. Unlike the previous example, no post-editing is needed to get this transcription up to scratch.
The output is also enriched with structural metadata, making it much easier to use the information in a structured format, such as a database, where each element is clearly defined and categorised. This allows for more advanced data handling and analysis, ensuring that each part of the document is accurately represented and easily accessible.
Which other kinds of documents are Field Models useful for?
In addition to the index cards shown above, there are many other document types that could benefit from the enhanced layout analysis that Field Models offer.
Newspapers
Newspapers are not only crucial for historical research, but, due to their complex but consistent layout, they are also excellent for use with Field Models. With accurate training data, a Field Model can learn to identify headlines, sub-headings, columns, images, and many other layout elements. Applying this layout analysis to large collections of newspapers can save a lot of time during the text recognition phase.
Newspapers are one of the document types most used with Transkribus. © KB, National Library of the Netherlands via Europeana
Legal records and forms
Legal records and forms contain consistent elements such as case numbers, names, locations and legal issues. Transkribus Field Models can automatically identify and extract these elements, speeding up the digitisation process. This helps reduce manual processing and increases the efficiency of research and document management.
Scrapbooks
Scrapbooks are, by nature, a collection of many different elements. From pictures and notes to transport tickets and newspaper clippings, they are limitless in the types of layout elements they can contain. With a Field Model, you can show Transkribus what all these elements look like, and train the AI to understand the layout of your individual scrapbook.
Scrapbooks contain an unlimited number of layout elements. © Irish Traditional Music Archive via Europeana
Sheet music
Applying Field Models to sheet music is currently the focus of several Digital Humanities research groups, who have successfully used Transkribus to separate the text and the notation elements. For more information, visit this article from BR Klassik.
Are there public Field Models?
Yes, there are! We’re excited to share our first public Field Models, which provide ready-to-use tools to make your document processing easier.
The Baroness of Blocks
The first one, called "The Baroness of Blocks", is designed to help you identify printed text blocks as single regions instead of separate paragraphs. It's particularly useful for documents with clear column layouts, making it a great starting point for creating accurate ground truth data.
The Baroness of Blocks © Transkribus
The Marginalia Monarch
Our next model, "The Marginalia Monarch", focuses on recognising marginalia - those handwritten or additional notes often found in the margins of documents. While it may need some adjustment for different types of marginalia, this model is a good place to start when it comes to extracting these important annotations.
Marginalia Monarch © Transkribus
How do I train my own Field Model?
Training a Field Model is a fairly straightforward process that doesn’t take too long to learn.
In principle, it is similar to training a text recognition model. You first provide Ground Truth training data; in this case, documents in which you have already tagged the different layout elements. Transkribus uses these documents to train the model, which can then be applied to the rest of your collection.
On our Help Center, you can find detailed instructions on how to train a Field Model for your documents, from preparing the training data to setting up the model.
Alternatively, you can watch this recording of our Field Models webinar for a good overview of how to they work and how you can best implement them in your projects.
